I recently came across an interesting issue at a customer site where Tanzu Kubernetes Grid (TKG) would fail to deploy or scale workload clusters. The customer had already successfully deployed a management and workload cluster. So they knew they had a working environment.
Running kubectl get machines would show machines in a Provisioning state.
$ kubectl get machines
NAME PROVIDERID PHASE VERSION
tkg-wrk1-control-plane-asxzc vsphere://321c4eb3-5g23-5698-2qws-a33g34e45cd4 Running v1.21.8+vmware.1
tkg-wrk1-md-0-45e67cdda3-8ag34 Running v1.21.8+vmware.1
tkg-wrk1-md-0-45e67cdda3-erfje Provisioning v1.21.8+vmware.1
tkg-wrk1-md-0-45e67cdda3-ej3ie Provisioning v1.21.8+vmware.1
tkg-wrk1-md-0-45e67cdda3-wie5t Provisioning v1.21.8+vmware.1
Targeting a provisioning node and running kubectl describe machine tkg-wrk1-md-0-45e67cdda3-erfje would show an error message ‘unable to find network’ followed by ‘resolves to multiple networks’.
Message: error getting network specs for “infrastructure.cluster.x-k8s.io/v1alpha3, Kind=VSphereVM default/tkg-wrk1-md-0-45e67cdda3-erfje”: unable to find network “/DC/network/nsxt-seg-tkg-wrk1”: path ‘/DC/network/nsxt-seg-tkg-wrk1’ resolves to multiple networks
A search on VMware’s knowledge base will bring up KB 83871. The KB references TKG 1.2 and 1.3 but it also applies to 1.4, which is the version being used here. The root cause is identified as being multiple Port Groups with the same name in vSphere.
In my customer’s case it was quickly identified they had a number of new vSphere clusters each with their own Virtual Distributed Switch (vDS) all being presented the same network segments out of NSXT. As a result each vDS would report the same TKG networks with the same name / port group.
The KB article’s resolution is to leverage vSphere permissions by creating a specific role and service account for TKG. Then assigning that role to only the required distributed port groups. While this is a valid solution, it’s clearly a little awkward to perform.
A much cleaner solution happens to exist. I have to thank a fellow work colleague here, Frank Escaros-Büchsel, for providing me the solution. It involves placing each Virtual Distributed Switch into its own network folder in vSphere.
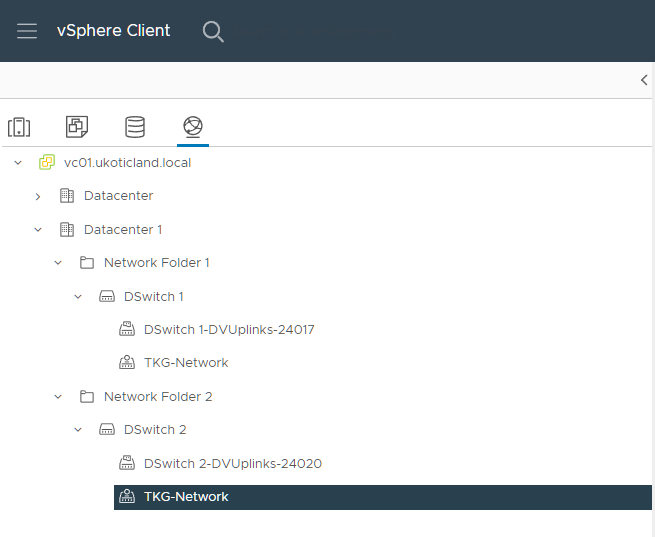
Now when you reference a vSphere network to use for a workload cluster you include the network folder in the network path. Existing built clusters may continue to experience the issue as they won’t take into account the new network folder. But all future clusters should now work fine.