Updated -- 12 Oct 2023: Important information from VMware GSS
I recently faced a situation where an ESXi host in my vSphere with Tanzu cluster went down unexpectedly. This lead to a SupervisorControlPlaneVM (VM) running on this host to go into a NotReady state.
The error
The first indication I had something was wrong in the environment was in Workload Management. Under the Clusters tab I had an error state with my Cluster.
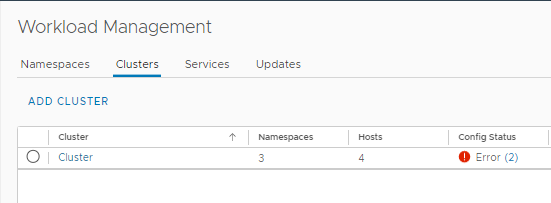
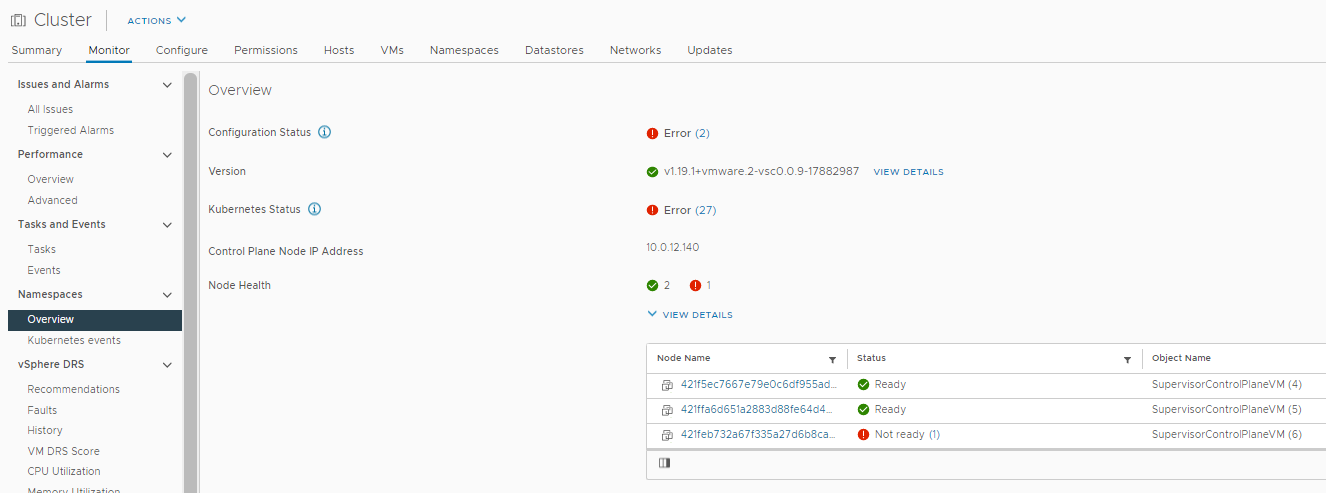
Looking at the Overview page under Namespaces of the cluster Monitor tab. I could see a number of errors. If I expanded View Details of Node Health I could see that a node was in a Not Ready state.
From the CLI, connecting into my supervisor cluster and running kubectl. I could confirm that one of the nodes was indeed in a NotReady state.

To troubleshoot or Not to troubleshoot
Now of course I could have begun to troubleshoot the issue and most likely spent the better part of my night trying to identify specifically what was causing this node to be in a NotReady state.
A better solution, at least in my mind, was just to have vSphere redeploy this node. My supervisor cluster on a whole was still functioning. I could still connect to it and manage my Workload Clusters running on it. So nothing was attaching me to this failed node. I decided that having vSphere redeploy this node was just going to be the easiest and fastest course of action.
Resolution
vSphere with Tanzu has a mechanism in place that makes rebuilding a Supervisor Control Plane VM relatively easy. It’s performed through the ESX Agent Manager. A not so well known service that assist with installing certain types of management VMs, such as vCLS VMs introduced in vSphere 7 or the Supervisor Control Plane VMs of vSphere with Tanzu.
Navigate to the Administration page of the vSphere Client. Under Solutions select vCenter Server Extensions.
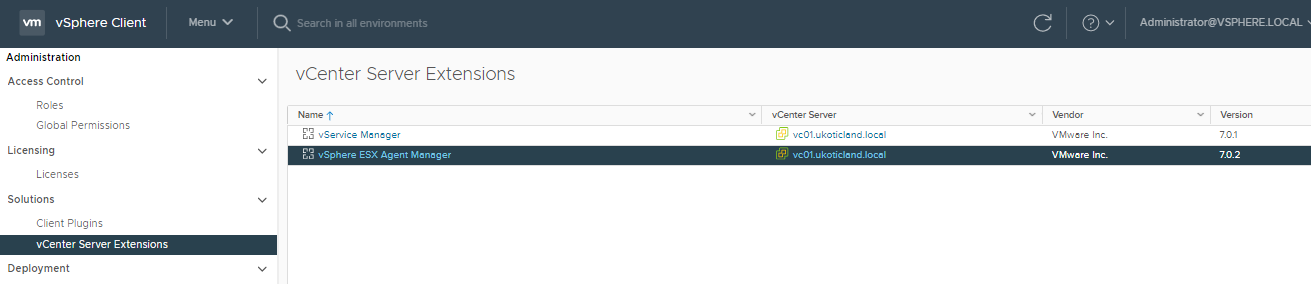
It’s here that you can select vSphere ESX Agent Manager for your respective vCenter, which will bring up a new page listing the VMs / Agents that it has installed and is managing.
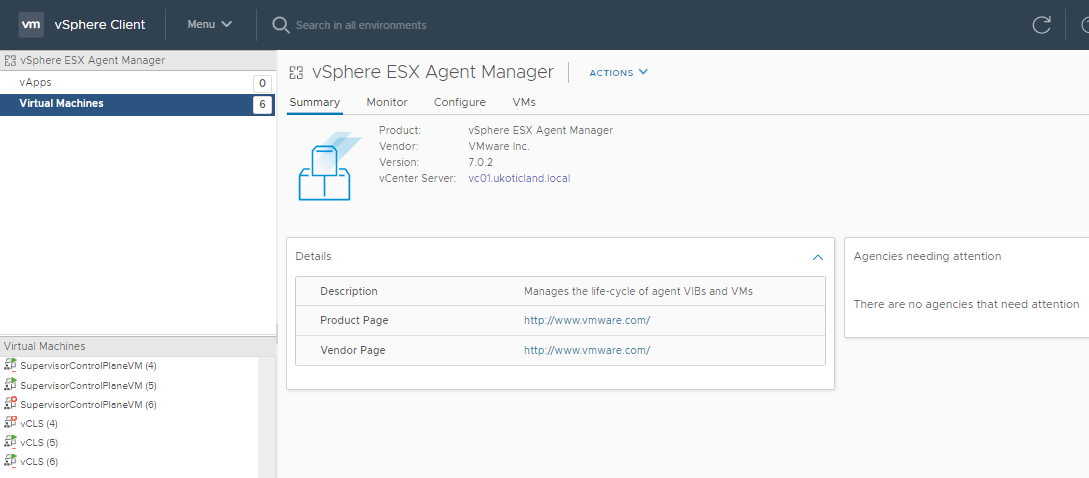
Select the Configure tab. Here we can see a list of so called, Agencies, in our environment. Your might have a number of different ones displayed in your environment. In this example we can see a vCLS Agency, which we can ignore. What we’re interested in is each of the vmware-vsc-apiserver ones which represent each of our Supervisor Control VMs.
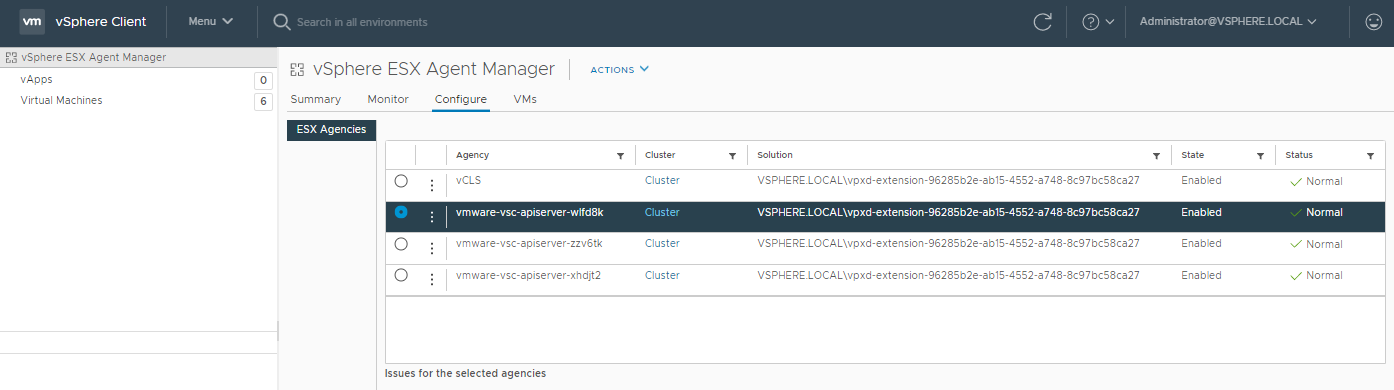
To identify the correct agency, we need to navigate back to our Supervisor Control VM (the one in a Not Ready state) in the vSphere Client and look in the Notes field. In the Notes field you will see EAM Agency and the specific Agency name for this Supervisor Control VM.

Armed with this information we can navigate back to the vSphere ESX Agent Manager page and select the correct agency. Clicking on the three dots brings up the option to Delete Agency or Resolve All Issues. Select Delete Agency.
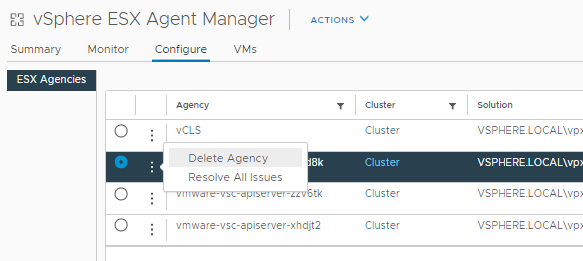
This will bring up a prompt to confirm the delete of the agency. Select Yes.
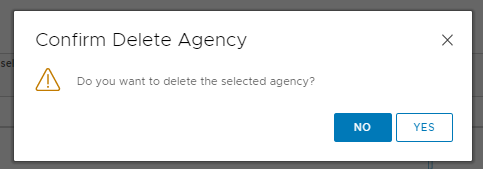
You will see a task that will remove the agency which will in turn delete the respective Supervisor Control VM. Shortly after the VM is deleted a new task will initiate and deploy a new Supervisor Control VM.

Back on the Overview page under the Monitor tab of the cluster you should see things start to stabilise and come green.
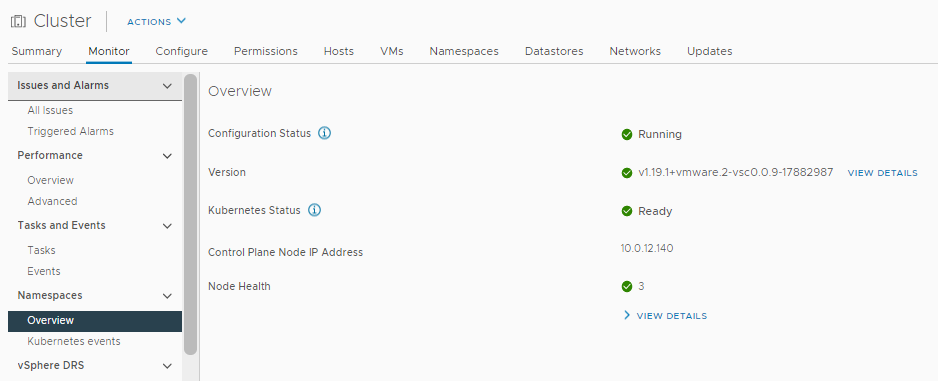
Over on the CLI using kubectl get nodes we can confirm that all nodes now have a status of Ready.

Be a little patient once a new Supervisor Control Plane VM is deployed. It can take a little bit of time for things to claim down and start reporting Ready.
Conclusion
It’s worth noting that I’m not aware of a correct process to delete / remove a single Supervisor Control Plane VM. If you do use this method you should be prepared to bear responsibility if something goes wrong. That said, I have seen this method referenced internally a number of times without issue.
Ultimately if this was a production environment I can see you wanting to find the root cause of the issue. That may lead you to performing some in-depth troubleshooting on the vCenter, trawling through logs, using the vmon-cli tool to inspect and troubleshoot the WCP Service, using kubectl to check the status of pods, etc.
But hey, this is Kubernetes… we don’t need to debug and troubleshoot. We just just delete and redeploy 🙂
Update: VMware GSS have recently brought to my attention some important information around this method and troubleshooting. Link can be found below
Troubleshooting vSphere with Tanzu (TKGS) Supervisor Control Plane VM’s (90194)
IMPORTANT NOTE: You can manually delete eam agencies from the web client via Menu -> Administration -> vCenter Server Extensions -> vSphere ESX Agent Manager -> Configure. Deleting an EAM agency will DELETE the supervisor control plane VM and a new one will be created. THIS IS NOT A VALID TROUBLESHOOTING METHOD FOR CUSTOMERS. Do not delete eam agencies without the EXPRESS permission of a VMware support engineer. Depending on versions and the existing health of the supervisor cluster it is entirely possible to render the entire cluster un-recoverable. If VMware Support finds evidence of a customer manually deleting an EAM Agency, they may mark your cluster as unsupported and require you redeploy the entire vSphere with Tanzu solution.
Hi,
I had to delete one EAM Agency to resolve an issue on one of my supervisor cluster plane.
The Broadcom support has confirmed the resolution of the issue.
Many Thanks!